本科的最后一门专业课:软件开发实践,要开发一个虚拟宠物医院学习系统,需要实现一个AI对话助手,具体的需求比较模糊。考虑到其他部分都是很低级的增删改查,因此一开始的想法就是能否将增删改查与AI对话相结合,提问的话问数据库中上传的药品/病例信息。
具体架构还是采取了RAG架构,本着一切从简的原则采取了Langchain.js纯前端实现,用OpenAI提供的api接口和Pinecone提供的远程向量数据库服务。
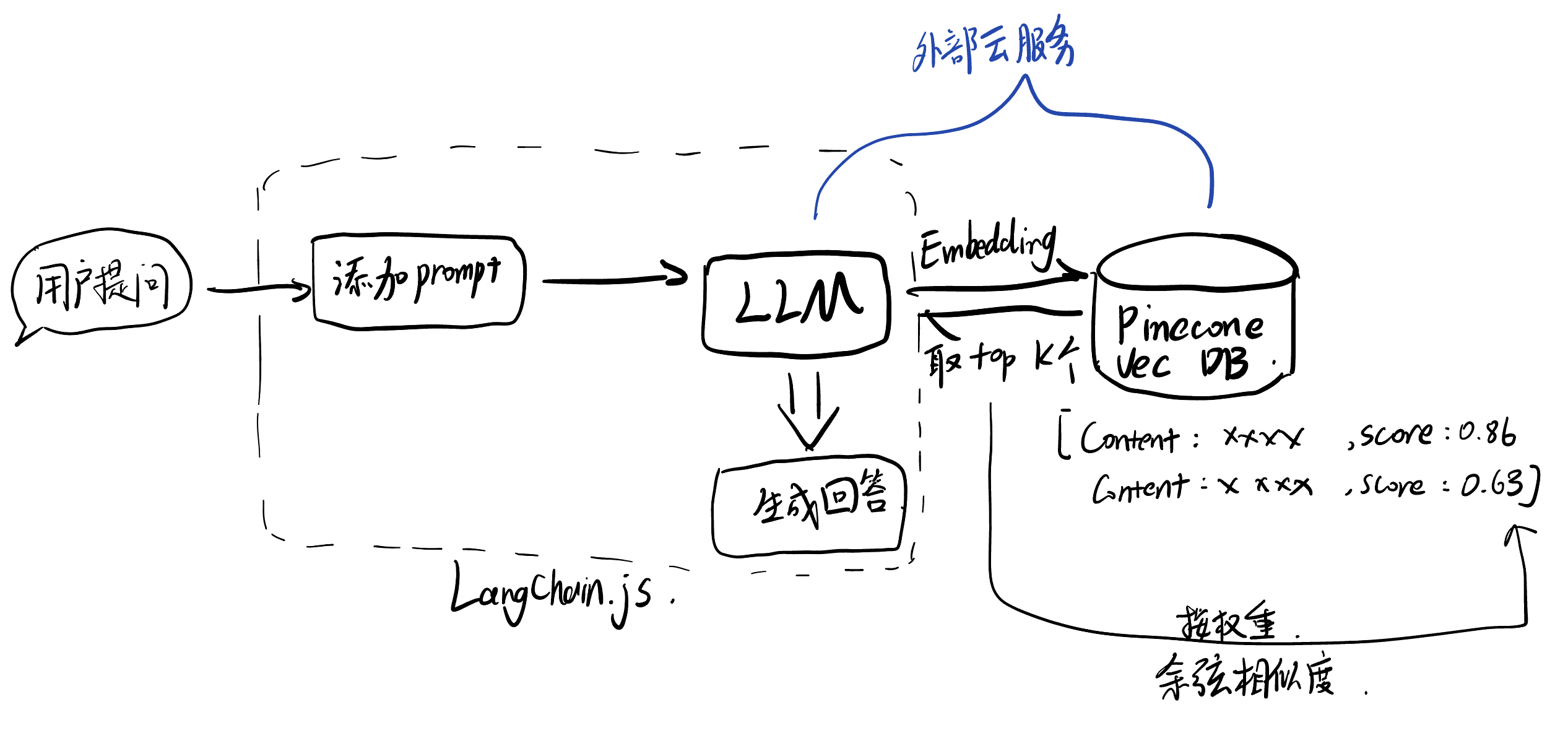
What is RAG(@GPT4):
RAG(Retrieval-Augmented Generation)是一种结合了信息检索和生成模型的技术,旨在提高自然语言处理(NLP)任务中的生成质量和相关性。它通过利用外部的知识源(如文档数据库或信息库)来增强生成模型的能力,特别适用于问答、摘要、翻译等任务。
RAG的工作原理
RAG模型主要由两部分组成:检索器和生成器。
- 检索器:
- 检索器的任务是从一个大型的文档集合中检索出与输入查询最相关的文档或信息片段。这通常通过向量相似性搜索实现,其中查询和文档都被编码为向量,通过计算向量之间的相似度来找到最匹配的条目。
- 生成器:
- 生成器通常是一个基于 Transformer 的语言模型,如 GPT 或 BERT。它使用检索到的文档作为上下文信息来生成答案。这使得生成的内容不仅依赖于模型内部的知识(训练数据中学到的),而且还依赖于外部的、具体的、与当前查询直接相关的信息。
RAG的优势
- 信息量更丰富:与传统的生成模型相比,RAG通过访问外部数据库增加了处理问题时可以利用的信息量。
- 准确性和相关性提高:在依赖外部知识进行回答的任务中,RAG可以提供更准确、更详细的答案。
- 灵活性:可以根据需要访问任何形式的结构化或非结构化数据源。
应用场景
RAG模型在多种应用中都非常有效,例如:
- 问答系统:能够生成详细的答案,尤其是在需要引用外部信息源进行事实查证时。
- 内容摘要:从一组相关文档中提取关键信息,生成凝练的摘要。
- 文章写作:在创建文章内容时,能够参考和整合多种资料和报告,提高内容的丰富性和深度。
技术挑战
尽管RAG技术提供了许多优势,但实现它也面临一些挑战:
- 检索效率:高效检索相关文档对于实时应用尤为关键,需要优化索引和查询处理。
- 数据同步:确保所依赖的外部知识库是最新的,这对于保证生成内容的准确性和相关性非常重要。
- 结果的一致性:生成内容需要与检索到的文档保持一致性,避免产生误导信息或错误。
具体实现
首先在Pinecone官网注册一个账号(省略了)
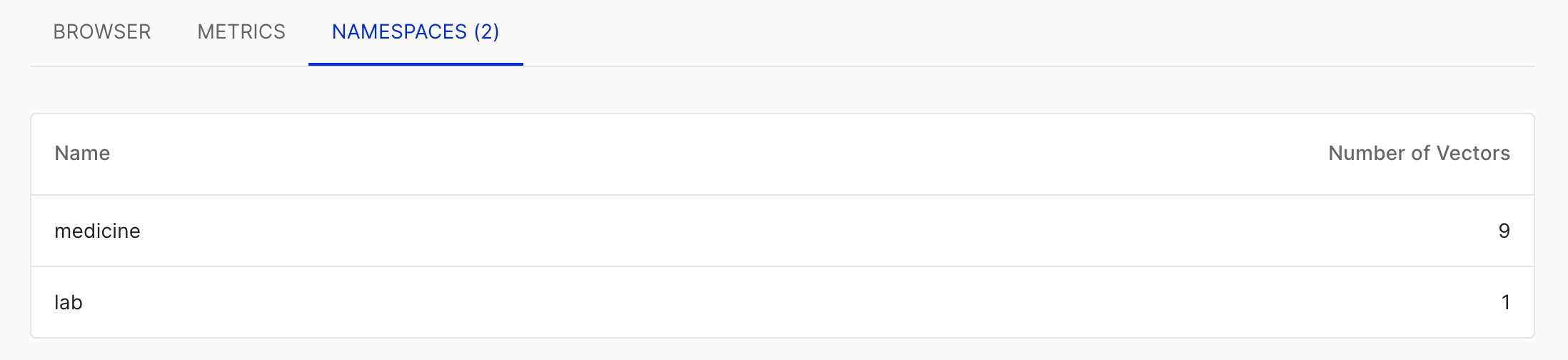
Pinecone中是分一个project可以有很多index,一个index下可以划分很多namespace。由于用的免费版只能有一个project,一个index,因此只能通过定义namespace的方式来区别不同的部分。
例如本项目有药品(medicine)和化验(lab)的查询,下面定义了这两个namespace。namespace是插入时的参数,不用手动设定。查询时可以在智能namespace下查找,十分方便。
对于每条record,namespace和ID不可修改,但是可以根据ID来更新其中的Values和metadata(就是下面的Key-Value键值对。
对于Values,就是执行embedding时转换后的数组。我前端用的是OpenAI的text-embedding-ada-002,转换后有1536维,因此这里的length就是1536。

查阅Pinecone的API接口,先写插入的函数,其中upsert就是首先看id是否存在,存在的话就更新,否则就插入。
export const pineconeAdd = async (id, namespace, input_text, metadata) => {
const embedding = await embedText(input_text);
try {
const insertResponse = await index.namespace(namespace).upsert([
{
id: `${namespace}${id}`,
values: embedding,
metadata: metadata
}
]);
return { success: true, message: 'Pinecone 添加成功', detail: insertResponse };
} catch (error) {
return { success: false, message: 'Pinecone 插入错误', error };
}
};
前端插入部分的逻辑,这部分跟往Mysql插入同时执行。更新也是一样:
// 插入数据到 Pinecone
if (newMedicine.value.saveToPinecone) {
const input_text = "药品名称:" + newMedicine.value.medicine_name + ",药品价格:"+ newMedicine.value.medicine_cost.toString() + ",疗效与用途:" + newMedicine.value.description
const insert_pinecone = await pineconeAdd(
medicine_id,
`medicine`, input_text,
{
medicine_name: newMedicine.value.medicine_name,
medicine_cost: newMedicine.value.medicine_cost,
description: newMedicine.value.description
}
)
if (insert_pinecone?.success){
ElMessage({
message: 'Pinecone 添加成功',
type: 'success',
});
}else{
ElMessage.error(`Pinecone 插入失败: ${insert_pinecone}`);
}
}
AI页面的处理逻辑:
if (queryType.value === 'medicine') {
const queryResponse = await pineconeIndex.namespace('medicine').query({
topK: 5,
vector: await embedText(userInput.value),
includeMetadata: true,
})
console.log("Query Response:", queryResponse);
responseText.value = "正在查询中...";
if (queryResponse?.data?.length === 0) {
responseText.value = "没找到相关信息";
return;
}
const formattedData = medicineFormatForLLM(queryResponse);
console.log("Formatted Data for LLM:", formattedData);
const llmQuery = getMedicineLLMQuery(formattedData, userInput.value);
console.log("LLM Query:", llmQuery);
responseText.value = llmQuery;
console.log(userInput.value);
const response = await chat.invoke([
new HumanMessage(
llmQuery
),
]);
console.log(response);
responseText.value = response.content as string;
}
用到的工具类与删除的函数:
export const medicineFormatForLLM = (queryResponse) => {
return queryResponse.matches.map(match => ({
id: match.id,
name: match.metadata.medicine_name,
cost: match.metadata.medicine_cost,
description: match.metadata.description,
score: match.score
}));
};
export const getMedicineLLMQuery = (data, userInput) => {
// 将数据转换为文本形式,用于作为查询上下文
const context = data.map(item => `ID: ${item.id}, 药品名称: ${item.name},
药品花费(单位rmb): ${item.cost}, 描述:${item.description}`).join('\n');
return `根据下列搜索到的药品信息:\n${context}\n用中文回答用户提问:\n${userInput}。`;
};
export const pineconeDelete = async (id, namespace) => {
const ns = index.namespace('medicine');
await ns.deleteOne(`${namespace}${id}`);
}
文本的检索就是首先将用户提问向量话,然后通过余弦相似度与value比较,取出前K个最相似的文本,然后让文本结合用户提问和自定义的prompt生成回答。
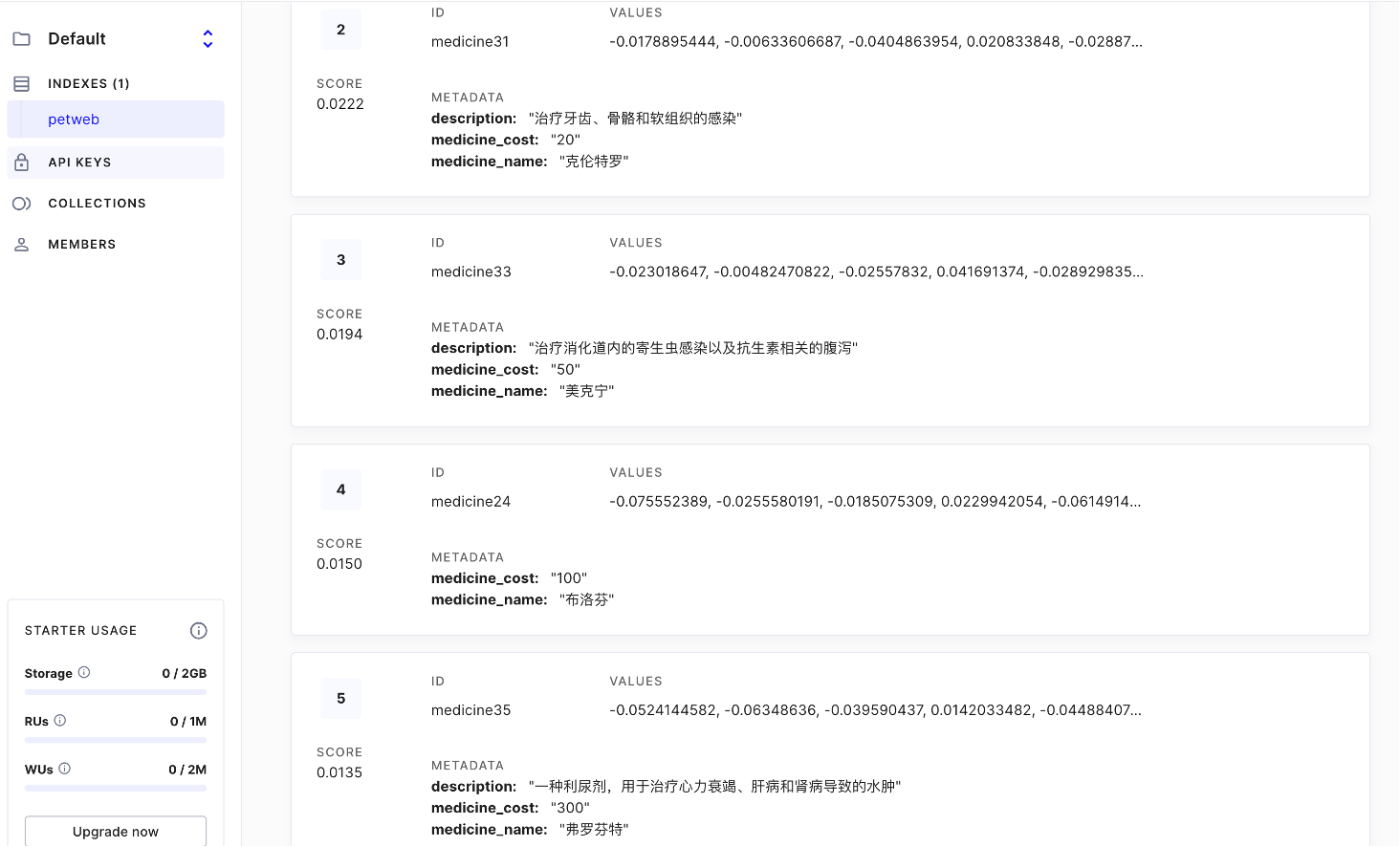
效果:


最后再吐槽下Langchain,javascript的版本和文档真的是写的依托答辩…本身用Python版本做毕设的时候用了个vectorStore,然后js版本的按照文档的来完全不能用,最后就只用到了一些最基础的功能,好像用不用都无所谓..